This material is licensed with the Creative Commons CC BY-NC 4.0.

Disclaimer: This is an initial draft. Comments are very welcome.
Henrik Bærbak Christensen, Computer Science, Aarhus University, 2023.
I have been doing software architecture as a researcher and teacher for more than two decades but it was only in late 2022 that I was gently pushed towards looking into energy efficient software and architecture or Green Coding. The concrete nudge came from a discussion with companies regarding our part-time education effort at University of Aarhus and IT-Vest: The companies stated that more and more projects demand an account for sustainability and climate considerations, and thus wanted our teaching to start focusing on these issues. I found that challenge intriquing. And also a bit puzzled: even though I am highly concerned about the climate crisis and tries to minimize (energy) consumption in my private life, I had never really considered the resource consumption of my own software.
This had to change...
And as always when venturing into a new field of software engineering, I was overwhelmed by resources, blog posts, research papers, you-tube videos, and talks. It is a confusing process to try to get an overview, when there are so many ideas and results out there.
My perspective is that of a practitioneer, wanting to build energy-efficient software; and as a teacher wanting to teach my students to do the same. So my search has primarily been for patterns, tactics, processes, methods that will help a software architect and software developer to do just that. And while finding concrete advice, try to classify them under some general, architectural, headline.
The Bærbak Green Architecture Framework is work-in-progress to get this overview of central architectural tactics.
Comments are most welcome by mail to hbc at cs at au at dk.
I base my software architecture teaching on the quality attribute framework from the book Software Architecture in Practice (Bass et al. 2021).
Here, the definition is
Energy Efficiency is concerned with the the system’s ability to minimize energy consumption while providing it’s services.
As such, it is a relative quality: You have two architectural designs, A and B, and both deliver some services to the users. However, one of these designs do so spending less energy than the other.
Bass et al. (2021) also define techniques and methods for achieving a given quality attribute, and name them:
Tactic: A design decision that influences the achievement of a quality attribute response.
Thus, the framework below describe rather concrete concrete and practical designs and coding practices that can be applied to (potentially) lower the energy cost of your software system.
Energy is a measure of amount of work done and measured in the SI unit Joule (J). When eletrical equipment is running, it uses energy, and the flow of energy per second, the power, is of course measured in J/s, Joule per second, or Watt. Watt is used so much, that often you will find energy measured in kWh, kilo-watt-hours, instead which is thus 1,000 Watts in 3,600 seconds = 3.6 x 10^6 J.
In my measurements below, I will often quote Watts. This, of course, only makes sense when comparing the same, steady-state, workload applied on two different architectures. If the workload vary (for instance if architecture A does less work than architecture B, because it simply is not performing as well) you will need to compute the average energy per transaction instead, ala how many mJ does each GET request cost?.
A computer has a number of hardware components that all need energy to function. However it is primarily the CPU that drives the energy consumption up or down.
For instance, buildcomputers.net quote these power data for a gaming PC:
| Component | Power Consumption | CPU Related |
|---|---|---|
| CPU (Intel Core i7) | 95 W | * |
| CPU Heatsink Fan | 12 W | * |
| High End Motherboard | 80 W | * |
| RAM Modules x 2 | 6 W | |
| High End Graphics Card | 258 W | - |
| Dedicated Sound Card | 15 W | - |
| Solid State Drive | 3 W | |
| 3.5" Hard Disk Drive | 9 W | |
| Case Fans x 4 | 24 W | * |
Here, components marked with '*' indicate components whose energy consumption correlates with the CPU: as the CPU works harder, it gets hotter, and thus need more cooling, requirering more energy by fans. The '-' components are of course not relevant for a server computer.
If you add up the RAM and persistent disk components, you end up with 18W, whereas the CPU related components add up to 211W. So the most power hungry component is the CPU.
CPUs are designed to conserve energy when work loads are low, in the form of power states, "C-states". C0 is the operating state whereas C3 is sleep. Some processers have up til 10 such states, each turning off more features of the CPU and thus saving more energy.
The overall best way to measure energy of a computer is of course to measure the energy consumption at the wall outlet, the plug power, as this is of course the truth about the full system.
However, an easier option is to use the on-cpu measurements that modern CPU's provide through the RAPL interface. While RAPL only measures on-chip power, they fortunately correlate closely, as shown later in Section: Utilize you Resources Efficiently.
On Linux, you can use the powerstat program to constantly monitor power consumption over a period and compute averages and standard deviation, as well as measure chip temperature and C-states. On Windows, the PowerGadget has similar features.
Papers and literature have different focus: saving energy on the mobile device, on web applications, on networks, on servers, etc.
Perhaps quite naturally, it is easier to find concrete advice on how to save energy on mobile devices: the implications of wasting energy is much more directly observable by the users.
My focus in my teaching is primarily on building server side architecture, and I have less experience in the realm of mobile app development, web applications, and other user facing systems. This bias is of course reflected in the set of tactics below.
I will briefly mention some numbers from experiments of my own through-out the paper. The exact experiments are detailed elsewhere, contact me if interested. Generally, all numbers refer to measurements using the RAPL interface of the CPU, and are thus actually conservative measurements, as the on-the-wall power consumption is higher. However, they do correlate as is shown in Section: Utilize you Resources Efficiently.
Numerous resources and experiments have contributed to this work, but I would like to emphasize one particular influential paper by Suárez et al., 2021.
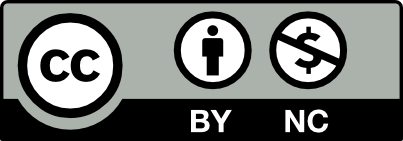
An overview of the framework is provided below:
It consists of three process tactics and seven architectural tactics.
Process tactics are decisions concerning the processes of building and maintaining an energy-efficient software architecture.
When the map doesn't agree with the ground, the map is wrong.
Gordon Livingston, "Too Soon Old, Too Late Smart", 2004.
As stated above, energy efficiency is about choosing architecture A over B, because A will deliver the same service using less energy. The question is then, how to come up with that better architecture A?
The present framework's architectural tactics section is of course all about that. However, as with design patterns, tactics must be adapted to the architecture at hand and what initially appear as a good choice may in fact turn out to be a lesser choice. The map doesn't agree with the ground.
So - the advice is to invest the time and effort into setting up a laboratory in which to measure energy consumption and to do experiments.
Setting up an energy lab entails:
Of course, the best lab uses the same computational equipment as used in the production environment. This is, however, not always feasible. Still, computers are computers so while exact numbers may not transfer, the trend will.
Virtualized computers do not allow access to on-chip energy data, for obvious reasons, which pose a challenge when running in the cloud. Here, the cost of running will most probably correlate with energy consumption.
Measurement and experimentation is not only for the purpose of finding the optimal architecture; it is also an important learning experience. I have had a lot of aha moments while experimenting, and often been surprised by just how much energy can be saved by doing A instead of B. All these experiences feed into a better intuition about what is worthwhile and what is not.
A great guide on making systematic and statistical significant measurements has been written by Luís Cruz (2021).
Software systems is used in various ways by various user groups for various purposes, but not all usage scenarios occur with equal frequency. Optimizing the energy consumption of a part of the architecture that handles that one transaction occuring once every tuesday night is probably less effective than optimizing that transaction which is executed 10,000 times a day. Little strokes fell big oaks.
So, focus your time and effort in energy optimizations where it counts.
Energy is often wasted simply because we do not know there was a problem. It is important to increase awareness about energy costs for all: architects, developers, testers, etc. Many minor design decisions are made by developers at keyboard time and all these "little strokes" add up. It is of course important that an understanding of best practices is common knowledge for all involved in developing and maintaining an IT system.
As written above, I have had numerous aha moments during my own experimentation which will influence the way I code in the coming years. Perhaps the best way to increase awareness for your teams is to set up that energy lab, and let them work on tactics in your system - and let them have these aha moments.
Perhaps, awareness should be extended to the end users of a system. Energy labelling of domestic appliances allow customers to choose the energy saving option. If our software systems could guide their users in the same manner, we may save energy by users adopting to use our systems in favorable ways.
Architectural tactics are decisions concerning the design of the architecture and decisions on how to program services and their connections.
The tactics are grouped within seven major categories. Actually, these tactics have equivalents in our everyday life, as indicated by the quote starting each category.
Turn off the lights when you leave the room.
It is a waste, but also a rather rather common mistake, to leave lights or equipment turned on, even when we do not use it.
In a similar vein, it is obviously sensible to turn of physical computers, or components of it, when not in use. A computer that is idling will spend less energy than a working computer (more detail later), but still it is energy used for no purpose.
A monolith architecture forces all modules/parts of an architecture to be scaled in lock-step. However, if you modularize your architecture using a microservice approach, individual elements can be scaled indendently.
As an example, a web shop must offer both functionality to allow browsing the catalogue of products as well as allow buying them. In a microservice architecture, these two behaviors would be implemented in different microservices and thus scaled independently, allowing both to be scaled up and down depending on seasonal sales.
There are several options for automatic scaling of services depending upon demand, like Kubernetes autoscaling and features in Platform-as-a-Service (PaaS) frameworks.
Note: If you do not make use of the independent scaling, a microservice architecture will generally be less energy-efficient than a corresponding monolith architecture. You will have more services running as well as more databases due to the decentralized data management principle.
I made an experiment in which the same server system was configurable to either run as a monolith (REST server + MariaDB) or as a microservice system (API Gateway + two REST servers, each with their own MariaDB). On the same workload and same perceived functionality as seen from the client, the microservice variant spent 36.6 mJ pr REST call on average compared to the monolith's 20.3 mJ. That is an overhead of 80.3%, or 1.8 times as much energy for the same behavior.
Cloud computing offers several service models, one of which is the Faas: Function-as-a-Service. The promise of this model is, that it has no idle state as the execution context is created on-the-fly for executing that single function, and removed just after.
Disclaimer: The creation of the execute-once execution context for the function of course also spends energy. Therefore there must be a tipping point in which it is more efficient to have a service model like PaaS or IaaS which does not have to create and destroy that context all the time.
On mobile devices, apps have an activity lifecycle which tells the app when the app is paused, resumed, stopped, etc, reflecting that the user is putting the app in the background, stops interactive with it, etc. These should of course be respected, so the app releases memory, stops accessing energy-costly sensors, and this way avoid spending energy when not needed.
Don’t put things in your suitcase, that will not be used.
We have probably all tried to pack our suitcase for that long awaited holiday, and when returning found much of the clothes in exactly the same condition as when it was originally put into it. Time, effort and energy wasted on transporting stuff for no reason at all.
Computing is similar - why transfer data that is never used?
Aka Zero Waste Code in Suárez et al., 2021.
Deployment units like '.exe' files, jar files, docker containers, and javascript need to be tranferred to the executing machine, and the larger these "bundles" are, the more energy is spent on transport, storage, and execution. Thus, we should strive to keep these small, and avoid they contain "waste code", i.e., code that is not necessesary for the programs functionality.
Open source reuse is wide spread through e.g. Maven Repository but often these libraries contain a lot of functionality that is not used, or contains similar functionality across the libraries your application depends upon.
This is even more pronounce in web applications in JavaScript as the deployment unit/code is downloaded per-visit and not just once.
Techniques exists to eliminate dead code, like tree shaking. In the Java space, the ProGuard tool can be used to reduce bundle size.
Docker containers are built upon a base image and picking the right one has a major implication on the resulting image size. I initially made my own base image for Java systems based upon Ubuntu 20.04 and a JDK11: this image is 914 MB. However, an environment that is based upon Alpine and just the JRE11 is only 148 MB.
In a similar vein, the size of the network packages should also be considered. Every byte transferred costs energy, so avoid transferring unnecessary data.
As always, quality attributes may conflict, and reducing the network package size by removing seldom used data may effect other aspects like modifiability: I usually put a "version identifier" in my messages to allow client and server to ensure they talk "the same language", but of course this information is seldom used while having an energy cost in every request and reply.
This tactic also relates to the format of the data, the Use Low Foot-print Data Formats.
Transferring data that is never used is a waste of energy. So to combat that defer the fetching until the data is actually used by the user.
One such technique for lists of data is to use pagination: instead of transferring, say 5,000 elements, transfer 50 elements at a time, and only transfer the next "page" of 50 elements when they are actually used.
Another technique is the Proxy pattern in which a light-weight, surrogate, object is transferred in place of a real, heavy-weight, object. The proxy contains just the information for fetching the real object, but will defer this fetch until the user actually needs it. One example is a large (web) page full of images and videos: Instead of transferring all images to begin rendering the first part of the long page, all images are represented by proxy images, knowing only the image's width and height as well as how to fetch the real image. Thus, odds are that images at the bottom of the page will never require a fetch, if the user decides to abondon reading the full page.
Buy 50 things at the super market once, instead of making 50 trips buying a single thing.
Having a shopping list of items you need for the next few days, can save quite a few trips to the super market. Our software is no different.
Many small network package transfers are more expensive (and slower) than a few larger network package transfers. This is sometimes referred to as chatty versus chunky interfaces.
Therefore when a client fetches data from a server, the client should try to envision what kind of related data may be requested in the "immediate future" or as a consequence of this request, and then fetch all the relevant data in a single bulk transfer, saving those imminent fetches.
As an example, object-oriented programming favors a fine-grained interface for getting data, with multiple getter-methods, one for each attribute of an object. The classic Person class with getAge(), getFirstName(), getSurName() is an example.
If such an object is an remote object in Java RMI or a Broker pattern architecture, assembling the person's data for presentation in a user interface will require lots of communication alas a chatty interface.
Instead, the pattern Batch Method POSA 4 should be employed. Batch method is an architectural pattern for implementing Bulk Fetch Data.
Either the server API should expose methods for bulk transfer, or some scheme of caching+bulk transfer could be employed to preserve the fine-grained API on the client side.
Of course, the issue is to guess what the 'immediate future' entails - caching is notoriously difficult to get right, and bulk fetches may lead to 'overfetching' which contradicts the Reduce Network Package Size tactic, and also have a tension with the Defer Fetching/Lazy Fetch tactic.
Another variant is to manage sampling rate: instead of uploading data every 1 second, then store samples for the last 15 seconds and then transmit them in one, larger, bulk transfer.
However, this is a strong tactic, as it saves energy at both ends of the connector: both the server-side as well as the client-side spends less energy on communication.
Note this tactic is closely related to tactic Fetch Data from the Proximity's "Cache Data Closer to User".
In my own experiments, I took a Hearthstone inspired card game which is a mandatory project for my second year bachelor students. The card game is designed in the object-oriented style (meaning fine-grained interfaces) and made into a network playable game using the Broker pattern. I wrote the 'by-the-book' broker solution, replicating the fine-grained, chatty, interface; and also wrote a variant that used a caching+bulk fetch scheme: all data related to, say, a card (name, owner, cost, strength, health, status, etc.) was bulk transferred and cached for five seconds in the client. As the UI constantly renders each card graphically it always requests all individual properties of the card, this reduces network traffic a lot. A load was applied and while the original server spent 5.66W (std dev 0.90W), the bulk fetch server variant spent 4.12W (std dev 0.79W), a saving of about 27%. And that 27% saving is on the server side alone; of course the client also spends less energy (I have not measured that effect, though).
Have a stock of supplies to avoid a lot of trips to the super market.
I guess most have tried started the cooking of today's dinner and in the middle of the process discovering that you do not have one or several of the ingredients. Having a stock means you do not have to go very far to retrieve it.
Caching is central technique in computing: store a copy of data locally in order to avoid an expensive fetching of data again.
Another example is Content-Delivery Networks (CDN) that caches global web sites on a set of geographically distributed servers so content is delivered from nearest server.
In the section above I described an experiment that saved 27% by caching object data for five seconds in the client, instead of requesting them from the server.
If two or more services communicate a lot, it makes sense to co-locate them, that is, host them on the same data-center rack, the same physical machine, or same processor to reduce the energy overhead of communication.
Databases can be sharded, that is, one database server may only have some of the total amount of data stored. If a good sharding scheme is employed that takes geographical distance into account, this can save energy. As an example, a database of global customers may be sharded so European customers are stored in a shard in Europe, while US customers are stored in a US shard, etc. Chances are that requests to the US database shard are related to US data and thus data is fetched from the near proximity.
Switch the 20 W halogen bulb to a 4 W LED bulb.
The EU adopted a regulation that phased out traditional incandescent bulbs with more efficient ones. An old 60W bulb emits about the same amount of light as a modern 5-6W LED bulb, so there is a large energy saving to be had.
Many of these tactics boils down to 'use an efficient X' for X being all the computational stuff we use...
In the paper Energy Efficiency across Programming Languages, Pereira et al. (2017) measures the energy spent on a set of benchmark programs in several different programming languages. They find that the choice of programming language does matter. Not surprising, interpreted languages like Python and Ruby spend quite a lot more energy to do the same computation than compiled languages like C and C++.
One objection to the study is that the benchmark programs are not that relevant for the software industry: how many companies earn their money from computing Mandelbrot?
I made an experiment in which I wrote the same simple REST service (Three endpoints: one POST of data, and two GET queries) in Java, Go, Scala, and Python. All implementations avoided log messages, and stored data in memory (no databases). As the service is simple, the code is relatively comparable, however the Java version was the template and a bit more elaborate than the other implementations. If we make the Java variant the baseline (at 8.6W std dev 0.3W for a throughput of about 1700 transactions pr second (tps)), the Go variant spent 3.5% less energy (8.3W std dev 0.2W), the Scala variant spent 27% more energy (10.9W std dev 0.4W), and the Python variant 112% more energy than the Java variant (18.2W std dev 1.2W). However, as the Python variant underperformed significantly: it could only manage about 1375 tps; the Python variant actually spends 162% more energy (that is 2½ times that of the Java variant!) when we compute the energy consumption pr transaction.
The bottom line is to prefer compiled languages like Go or C++, or languages that have a long tradition for highly optimized virtual machine execution, like Java.
Efficient algorithms is at the heart of computer science and taught in numerous courses at computer science departments. And it should be evident for all developers that a binary search is more efficient than a linear search. And as energy consumption is linked to the time spent by our CPU executing to find the result of a computation, the faster algorithm will probably also be the one to spend less energy.
There is also an indirect aspect of this tactic, namely providing the algorithms with the proper "hints". One such is making proper indices in databases, so common queries can be executed with the minimal amount of energy. (For instance, to avoid The Ramp: the more data has been accumulated, the longer each query takes).
Some data formats are more verbose than others, and of course, the less data to store and transfer the better.
For instance, XML is more verbose than JSON. Binary data is generally more compact than human-readable formats. And vector formats like SVG is more compact than (large) raster images like PNG.
Compression of course also helps, but must be considered with respect to the extra energy to do the packing and unpacking.
Another aspect is that the algoritms used to produce and parse the dataformats (like XML versus JSON marshalling) may also vary in energy efficiency. As always, it is best to measure and experiment.
Today there are many different databases to choose: traditional relational databases like MySQL and MariaDB, to NoSQL databases like MongoDB, Redis, MemCached, and others.
And databases differ with respect to how much energy they consume for the same workload.
In my own experiment, I measured a simple REST service (three endpoints, one for storage (POST) and two for queries (GET)) with a Redis and MongoDB backend. With the MongoDB backend as base line (21.3W std dev 0.5W) for a given workload, a Redis backend spends 31.0% less energy (14.7W std dev 0.3W).
As always, there is a trade off. Redis is a simple key-value store, and does not support advanced queries like MongoDB or a SQL database. But... If you do not need that, why pay the extra energy for nothing?
Note: NoSQL databases are built with replication in mind to provide high availability and ensure data is never lost. However, obviously having five replicas spends more energy than having three. Consider just how valuable your data is and the degree of required replication.
Jacobs(2009) is an excellent paper about the challenges of handling big data. A key point is that even software engineers need to understand the underlying physics of the hardware they use to store their data. And that dictate that sequential reads of data (reading pattern match the original writing pattern) is much faster (and thus much cheaper) than random reads. The implications is that your algorithms should be focussing on one-pass over data in the write order and generally denormalizing data is preferable, as JOINS will require random read patterns.
I replicated Jacobs's experiment (finding median age for populations, grouped by sex and country), with 100 million data points stored on a spinning disk. First I replicated Jacobs's algorithm which does a one-pass computation over the full data set, stored in a bit-packed file - this cost 1.94 kJ. Next I read that data set into MongoDB, and made a naive JavaScript procedure to compute the same - this cost 809 kJ. If I rewrote the JavaScript procedure into a single-pass over the data - it cost 20.0 kJ. And finally, I read the data set into MariaDB and made a single select statement - that cost 38.5 kJ. The same computation, the same result - but with widely different costs in terms of energy.
Prepare several items in the oven at the same time.
Once an energy expensive equipment, like an oven, is operational, we might as well take full advantage of the energy investment. For the oven, we can try to bake/cook as many things at once as possible.
CPU's are no different. Even though modern CPU's have a complex set of partial sleeping states (C-states) that saves energy, an idling CPU still consumes quite a lot of energy while - well - doing nothing. This is the energy proportionality concept, and examples are shown below.
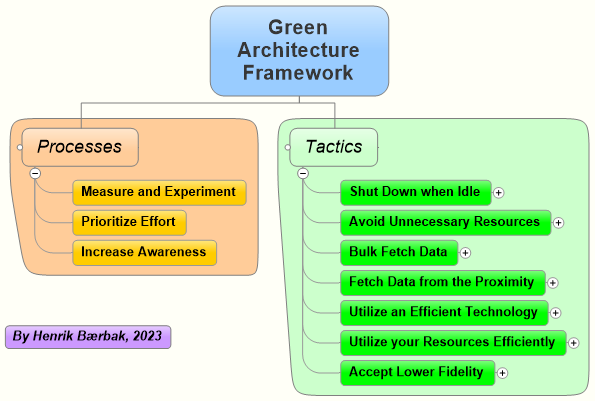
The image above is from a 2012 Fujitsu desktop computer. It is a graph of CPU load versus Power in Watts. The blue curve is the RAPL measured power (CPU+RAM only) while the red curve is the at-the-plug power measured with a Nedis smartplug. Thus the red curve is the "true power" used by the full machine, including fans, motherboard, harddrives, etc. The key point is that the idling computer spends about 10W while a fully loaded computer spends about 43W. That is, a computer doing nothing spends about 20-25% of the energy a fully utilized computer does.
The same measurement on a small business server, using the Xeon processor, the Fujitsu TX-100 (also from 2012) show an even more pronounced curve.
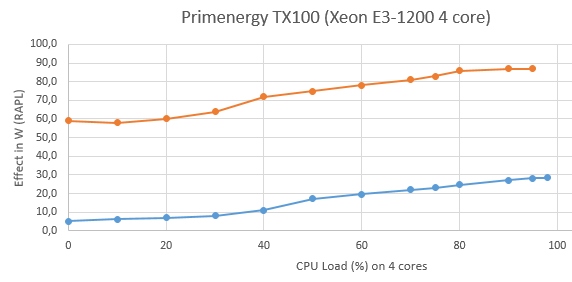
Here, the idling computer spends about 2/3 of a fully utilized one. These measurements align with data in NRDC Aug 2014 which states "servers still use 30 to 60 percent of their maximum power when utilized at 10 percent or lower capacity, doing little or no work.".
The bottom line is that computers should be working, otherwise we shall turn them off.
One of the characteristics of cloud computing is the pooling of resources: a single physical machine (the host) will host a number of virtual machines (the guests). Thus, if virtual machine A currently is idling, then the full capacity of the CPU is available for virtual machine B, and vice versa. This way, overall higher utilization can be achieved. The NRDC Aug 2014 report states that companies on-premise data centers generally do a lesser job of achieving high utilization than public cloud providers, mainly due to overprovisioning: the fear of not being able to handle peak loads means too many servers idle most of the time.
Other factors are in favor of big data centers, for instance, when partnerships are stroke with local district heating companies so the heat produced can used to save energy elsewhere.
This tactic relates to Utilize the CPU at the R/U Knee and Independent Scaling of Modular Architecture.
Creating threads/database connections is expensive, as it takes CPU, memory, and require garbage-collection), and it is thus more efficient to make a pool of them, so they are reused instead of constantly being created and destroyed.
In my own experiment, I tried to refactor a simple service's use of a 'db-connector-per-request' with a C3P0 connection pool for MariaDB, and saved about 29% energy per request.
Queue Theory is a mathematical model of waiting lines/queues. As many server system are reactive, that is, responding to requests from a large population of users that act independently and the incoming requests thus arrive according to a Poisson process, it can be used to predict the total reponse time as a function of the utilization of the system. A key result is that the response time R is related to system utilization U as: R = S/(1-U), where S is the service time, the response time of a request when there is no load on the system. The utilization is basically a percentage of the system's maximal capacity.
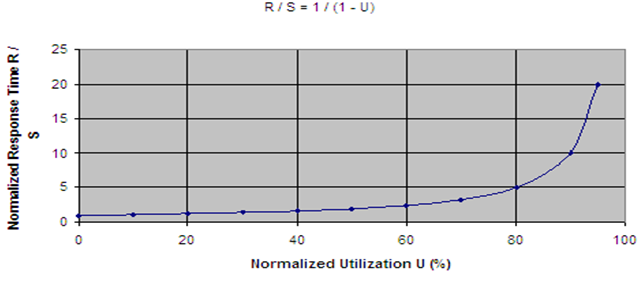
Paraphrasing this relation, the system is responsive up to a point around 70%-95% after which the response time grows fast, and the system becomes slow and inresponsive. It is the same effect that happens on highways - when utilization is high (too many cars on the road), queues form and the trip takes much longer compared to driving on an empty highway.
Example: S = 10 ms, then when U = 0% then R = S/(1-U) = 10 ms. However, if the system/CPU is highly loaded and U = 80%, then R = S / (1-0.8) = S / 0.2 = 50 ms. That is, it takes five times longer (on average) to get a response than if the system was in a low load situation.
So this tactic tell us to balance the wish for relatively low R on one hand with the wish for maximum U on the other (as each CPU work cycle is the least expensive at max U) we should strive for hitting U ~ 70%-95% on our physical machines.
Modern machines, operating systems, kubernetes clusters, services, and databases comes with numerous parameters to be tweaked For instance is a Java VM is configured with too little memory, a disproportional amount of CPU is spent on garbage-collection, meaning higher energy consumption. Docker containers can be tweaked in many ways. Operating systems can be tweaked in numerous ways, including large-pages and NUMA.
The short story: tweak them to maximize energy efficiency.
Turn the room temperature down from 21° to 19°.
Sometimes we must just accept lower quality to reduce our consumption of energy. Like accepting the room temperature is lower than usual.
One of the low-hanging fruits is to consider the resolution of images and video. A high resolution requires more storage, more network usage, and more processing. So consider if 1080p is really necessary, or 720p can do?
Can we downsample the images in a bulk process once on the server, so all future requests push images at a lower resolution?
Lossy formats like JPEG for images or MP3 for audio reduces the required storage space and network transmission.
This of relates to the Use Low-footprint Data Formats tactic.
Monitorability of a server architecture is an important quality attribute: The ability to survey the health of the server-side as well as provide diagnostic information in case of failure.
Monitoring in the form of logging, however, of course comes with an energy price tag. Running an correctly configured ELK stack is resource demanding. As a curiosity, I teach a course in microservices in which all curriculum aspects and learning goals are easily handled using Docker Engine and Docker Swarm which runs nicely on a student's laptop---with one exception, namely the topic of logging. I first looked into using ELK but the demands on hardware far exceeded what I could ask for a student have access to; and finally I decided to use a commercial cloud-based logging service with a free introductory tier.
So - the advice is to consider logging carefully ala Do we really learn anything by adding this log message? and review your code base for those log messages that were more akin of debug messages in the early stages of the systems life-cycle, that can be removed.
I did an experiment with a microservice with 3 REST endpoint, that simply made one log message per incoming request; compared to a baseline of no logging. The service was run as a Docker container, with the standard docker logging system, that simply writes log messages in JSON format to the harddrive (in my case a spinning disk). It turned out to cost 12% less energy to have logging turned off.
Aka Avoid Impulsive Consumption in Suárez et al., 2021.
Dynamic web content requires computations server-side for each request. So the question is if this server-side computation is really necessary? It can save energy to replace it with once-per-hour/once-per-day/once-per-X server side batch processing to compute a static web page that is served instead.
Software has a tendency to always grow. Features are seldom removed from software. Wirth's law expresses this as software is getting slower more rapidly than hardware is becoming faster.
Features that are seldom or even never used still contribute to wasting storage, wasting network transmission time and bandwidth, and loading time - all using energy.
So perhaps it is about time that we start wondering what to remove from our system, instead of only considering what more to put into them. Or give the user an option of getting a core system (with a green energy label) or getting a full system (with a red label).
Not so much of an experiment but rather an observation, I have provided my students with a VMWare virtual machine with course software since 2016. The image has been based upon Lubuntu Desktop, as I strive to make the image as small as possible. However, even Lubuntu grows significantly. Lubuntu 16.04 LTS's ISO disk image file is about 950MB and ran nicely in a VM with 2GB RAM. Today I use Lubuntu 22.04 LTS but its ISO disk image is 2½ times larger, and sometimes have issues with running in 4GB RAM. And the depressing aspect is - that the tooling and course code is about the same in 2016 as it is in 2023. I get no improvements, only more seemingly dead weight.
This tactic, of course, relates to the Reduce Bundle Size tactic.
Sensor fusion is a technique used in mobile devices for lowering energy consumption when using sensors. The classic example is that of the GPS which can estimate the exact location of the device accurately, but it is a energy hungry device and should be used sparesly. Thus to continously monitor the movement of a device for, say, a running app on a mobile phone, the position can be estimated by using the accelerometer, as this sensor is much less energy-consuming than GPS. Thus the two sensors are fused to one logical sensor with overall less energy consumption.
For reference: